A recent interesting phenomenon is that machine reading comprehension suddenly began to heat up. Let's take a look at the related content with the network communication Xiaobian.
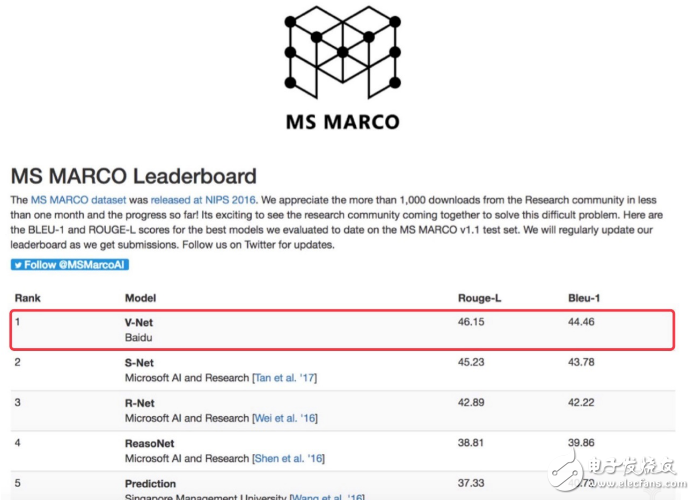
On February 21st, the V-Net model developed by Baidu's natural language processing team topped Microsoft's MS MARCO (Microsoft MAchine Reading COmprehension) machine reading comprehension test with a Rouge-L score of 46.15.
Read the question or read you? Stripping the mysterious coat of machine reading comprehension
In addition to the previous SQuAD competition at Stanford University, teams such as Ali, Harbin Institute of Technology and the United Laboratories have surpassed the human average. This means that the two top events in the field of machine reading comprehension: the records of MS MARCO and SQuAD have been broken by the Chinese team.
But in the midst of the lively "arms race", the depth of the machine reading comprehension field is not a sigh of relief. Various controversies and debates are taking place behind this "machine answer big show".
For example, why is Microsoft going to start a new data set and competition after SQuAD? Why is the academic debate about machine reading comprehension constantly?
These questions may ultimately be attributed to a question: What is the use of AI for reading comprehension?
Let's talk about the "reading and understanding circle" of the rivers and lakes, and the future of the foreseeable technology application.
Two big data sets confrontation: problems and controversies in machine reading comprehensionThe so-called machine reading comprehension, the basic concept is very similar to the reading comprehension questions we made when we went to school. It is also a piece of material and questions, so that the "candidates" give the correct answer. The difference is that only the protagonist of machine reading comprehension becomes the AI ​​model.
The game reading comprehension field, like Stanford's famous AI competition ImageNet, consists of an official data set + a running race. The major technology giants and AI research teams from world-renowned universities are the main players.
Baidu’s participation in the machine reading comprehension competition is MS MARCO released by Microsoft in late 2016.
What's interesting about this event is that the training data it uses is the questions and answers that Microsoft collects from real users in product practice.
The problems in this data set are all from BING's search log, and then the manual answers obtained from these questions are compiled as training data. The advantage of this is that the AI ​​model can be learned, trained, and reversed through the context closest to the real application, completing the small goal of “learning to useâ€.
It is widely believed in the circle that Microsoft is not so easy to collect a data set derived from a real network, and it is hoped that SQUAD of Stanford University will be hard.
Earlier in 2016, Stanford University team produced a data set to test the reading comprehension of the AI ​​model. Unlike MS MARCO, SQuAD's main training data is 536 articles from Wikipedia, and more than 100,000 questions and related answers raised by humans after reading these articles.
This kind of data setting, which is very similar to the campus exam, has been controversial since the day of its birth. For example, Yoav Goldberg, the big man in the NLP field, thinks this data set is a bit too one-sided. Where SQuAD is accused, it can be divided into three levels:
1. The problem is too simple. The answer to the question is mainly derived from a fragment in the document, which is rarely encountered in real-world scenarios.
2. Insufficient data diversity. SQuAD has only more than 500 articles, the content is not rich enough, and the trained models are questioned to be difficult to process other data or more complex problems.
3. Generality is not strong. In order to facilitate the running of points, the problem structure of SQuAD is relatively simple, and the machine involved in "reasoning" is weak, which leads to its practicality being suspected several times.
A simple example to describe the difference between the two data sets: the answer to most of the problems in SQuAD comes from the document itself, from the document "copy and paste" can complete the answer, this mode is more convenient, but objectively correct The types and types of answers are limited, and the problems built on SQuAD are usually more straightforward. The problem of MS MARCO is more inclined to the real language environment, and it needs the intelligence reasoning context for analysis.
Radish cabbage has its own love. Some people think that SQuAD is the most convenient machine to read and understand the game. Some people insist that MS MARCO is the closest competition to human question and answer habits. But there may be a consensus behind the debate: the applicability of machine reading comprehension has begun to receive widespread attention from the industry.
Attack data set: AI reading also attaches importance to "quality education"Of course, MS MARCO's data set structure is also controversial. But the similar "reading from life" machine reading comprehension training data set is growing. Summarizing this trend in one sentence, probably everyone found that it is necessary to change the AI ​​from "test-oriented education" to "quality education."
The compact and clear-cut SQuAD, while showing the test results of the AI ​​model very conveniently, is always blamed for its scalability and practicality. Many scholars believe that this data set has been excessively "examined", which led to its ultimate competition for competition.
Models trained directly from Internet text and product practice issues are considered to be closer to applicability.
In fact, think carefully, machine reading and understanding of this technology, has never been the "ivory tower" on paper, in the Internet applications we are already familiar with, there are a lot of problems that can only be solved by machine reading comprehension.
For example, when a user searches for an answer in a search engine, the traditional solution can only rely on user mutual assistance to answer, and the correctness and efficiency are seriously insufficient. However, if the agent answers, it cannot be processed by simply filling in the blanks. For example, there will never be a user asking "() is the longest river in China?" In more cases, users will ask complex questions and need complete solutions and suggestions. Then, learning the material and answering the questions from the real question data is almost the only way for AI technology to meet the upgrade of the search engine experience.
Another example is the recent controversial content recommendation area. Today's headlines have recently been repeated, largely due to public opinion accusing them of relying too much on keywords to recommend algorithms, ignoring the user's need for article depth and knowledge. One of the reasons for this situation is that the algorithm has insufficient machine reading comprehension ability, can't read real Internet materials, and gives personalized recommendation results.
In addition, voice assistants, intelligent customer service and other fields rely heavily on machine reading to understand real problems, real Internet materials, and AI capabilities to give complete answers. Training AI from real data may be the only way to solve these problems.
Chinese, General, Application: Foreseeable Future of MRCWhen we guess the future of machine reading comprehension, we will see several obvious trends.
First and foremost, most of the training data sets and competitions for machine reading comprehension are concentrated in the English field. This cockroach is being broken step by step.
For example, Baidu released a full Chinese data set DuReader similar to Microsoft MS MARCO last year. The first wholesale data set contains 200,000 real questions, 1 million Internet real documents, and 420,000 manual written answers. It can be seen that while the Chinese team challenges the English machine reading comprehension record again and again, the machine reading comprehension directly affecting the Chinese world should be not far away.
On the other hand, how to generalize and ubiquitize the technical capabilities of machine reading comprehension and fit with various other NLP technology systems seems to be a topic of great concern. Let the machine "understand", but also can be summarized, can think, can create, outline the complete Deep NLP era, has also been put on the agenda.
Furthermore, the application of machine reading comprehension to search, Q&A and other application areas is increasing, and the number of application cases that generate real value is increasing. I believe that in the near future, machine reading and understanding tools and integration can penetrate into all walks of life and become a mainstream solution in the information world.
A relatively high probability situation, probably in the near future, we will feel a kind of experience improvement that is difficult to describe but actually exists in the information flow. That's because the machine is "reading you" rather than "reading questions."
10 Mm Nano Tip,Smart Board Touch Screen Pen,Electronic White Board Pen,Infrared Touch Screen Pen
Shenzhen Ruidian Technology CO., Ltd , https://www.szwisonen.com