Abstract: As a commonly used coding method, Huffman coding, many people are not clear about its principle and application. This paper mainly explains Huffman coding principle and application examples and algorithm flow chart.
Huffman coding definitionHuffman Coding, also known as Huffman coding, is a coding method. Huffman coding is a type of variable word length coding (VLC). In 1952, Huffman proposed an encoding method that constructs the codeword with the shortest average length of the heterograph head based on the probability of occurrence of characters, sometimes called the optimal encoding, which is generally called Huffman encoding (sometimes called Hoff). Man coding).
Huffman coding principle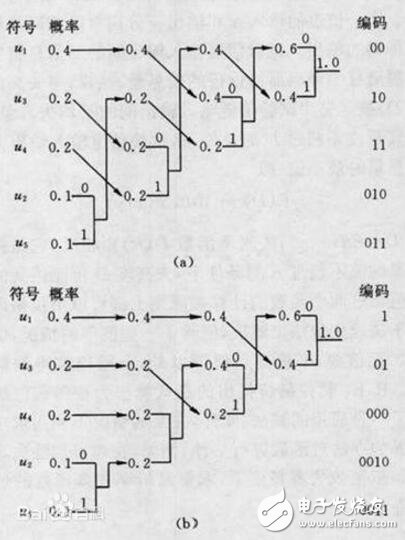
Let a source generate five symbols u1, u2, u3, u4 and u5, corresponding probability P1 = 0.4, P2 = 0.1, P3 = P4 = 0.2, P5 = 0.1. First, the symbols are queued by probability from large to small, as shown. When encoding, starting with two symbols of minimum probability, one of the branches can be selected as 0 and the other branch is 1. Here, we choose the branch to be 0 and the lower branch to be 1. The probabilities of the encoded two branches are then combined and re-queued. Repeat the above method multiple times until the merge probability is normalized. It can be seen from Figures (a) and (b) that although the average code lengths are equal, the same symbol can have different code lengths, that is, the encoding method is not unique, because the two paths are combined and re-queued. There may be several branches with equal probability, which makes the queuing method not unique. In general, if the newly merged branch is discharged to the uppermost branch of the equal probability, it will be advantageous to shorten the code length variance, and the coded code is closer to the equal length code. Here, the coding of (a) is better than (b).
The codeword of the Huffman code (the code of each symbol) is an isopreamble code, that is, any codeword will not be the front part of another codeword, which allows each codeword to be transmitted together without intermediate In addition to the isolation symbol, as long as the transmission does not go wrong, the receiver can still separate the codewords, so as not to be confused.
In practical applications, in addition to using timing cleaning to eliminate error diffusion and buffer storage to solve rate matching, the main problem is to solve statistical matching of small symbol sets, such as black (1), white (0) fax source statistical matching, The extended symbol set source is composed of 0 and 1 different length runs. Run, refers to the length of the same symbol (such as the length or number of consecutive 0 or a string 1 in the binary code). According to the CCITT standard, it is necessary to count 2 & TImes; 1728 kinds of runs (length), so that the amount of storage at the time of implementation is too large. In fact, the probability of a long run is small, so CCITT also stipulates that if l represents the length of the run, then l=64q+r. Where q is the primary code and r is the base code. When encoding, the run length of not less than 64 is composed of a primary code and a base code. When l is an integer multiple of 64, only the code of the main code is used, and the code of the base code does not exist.
The main code and the base code of the long run are encoded by the Huffman rule. This is called the modified Huffman code, and the result is available. This method has been widely used in document fax machines.
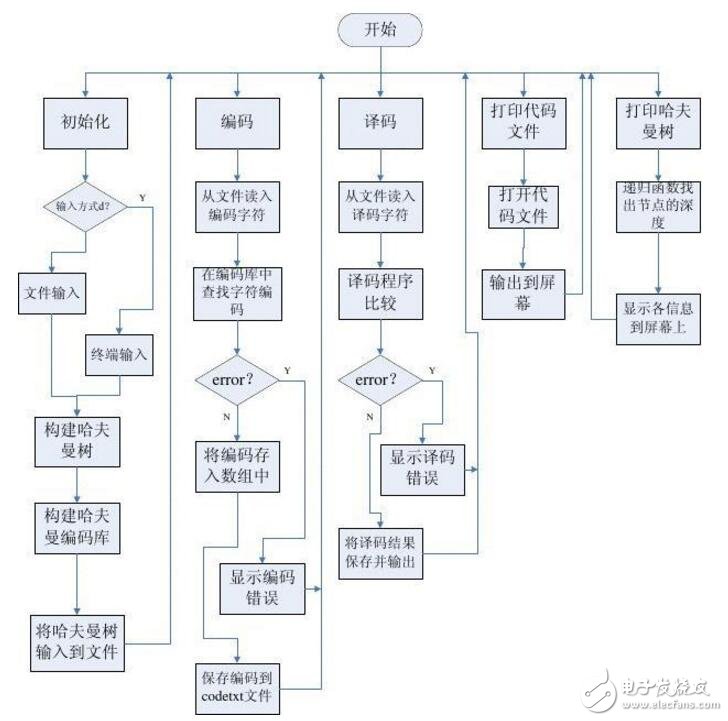
Huffman coding algorithm flow chartThe Huffman coding algorithm is an algorithm for finding the optimal path. First, find the smallest two nodes in all the nodes that are not assigned the parent domain, add their full values, form a new node, and put it. Marked as the parent of the original two smallest nodes. This calls recursion and finally becomes a complete Huffman tree. Then traversal coding is performed for each node to obtain the final Huffman coding library. The flow chart is as follows:
The process of the Huffman algorithm is: counting the frequency of occurrence of each character in the original data; all characters are arranged in descending order of frequency; establishing a Huffman tree: storing the Huffman tree in the result data; re-encoding the original data to the result data. The Huffman algorithm implementation process is shown in Figure 3.
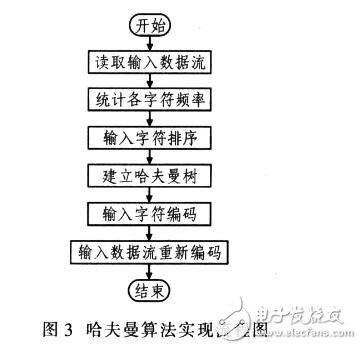
The essence of the Huffman algorithm is to re-encode the characters themselves for statistical results, rather than encoding repeated or repeated substrings. Practical. The frequency of occurrence of symbols is not predictable, and it requires statistical and coding twice, so the speed is slow and cannot be practical. The adaptive (or dynamic) Huffman algorithm cancels the statistics and dynamically adjusts the Huffman tree when compressing data, which increases speed. Therefore, Huffman has high coding efficiency, fast calculation speed and flexible implementation.
Issues to be aware of when using Huffman coding:
(1) Huffman code has no error protection function. When decoding, the code string can be decoded correctly if there is no error; if the code string is wrong, increase the coding and improve reliability.
(2) The Huffman code is a variable length code, so it is difficult to find or call the contents of the compressed file at will and then decode it, which needs to be considered before storing the code.
(3) The implementation and update method of the Huffman tree is very critical to the design.
Huffman coding application exampleHuffman coding, the main purpose is to achieve data compression.
Let a message be given: CAST CAST SAT AT A TASA. The set of characters is { C, A, S, T }, and the frequency (number of times) in which each character appears is W = { 2, 7, 4, 5 }. If each character is coded in equal length A : 00 T : 10 C : 01 S : 11, the total code length is ( 2+7+4+5 ) * 2 = 36.
If the unequal length coding is given according to the probability of occurrence of each character, it is expected to reduce the total coding length. The probability of occurrence of each character is { 2/18, 7/18, 4/18, 5/18 }, and the rounding is { 2, 7, 4, 5 }. Huffman trees are established by taking weights for each leaf node. The left branch is assigned 0, and the right branch is assigned 1 to obtain Huffman coding (variable length coding). A : 0 T : 10 C : 110 S : 111. Its total code length is 7*1+5*2+( 2+4 )*3 = 35. It is shorter than the case of equal length coding. Huffman coding is a type of prefixless coding. It will not be confused when decoding. The binary tree with the smallest weighted path length is the Huffman tree. In the Hoffman tree, nodes with large weights are closest to the root.
Huffman algorithm
1. Construct a forest F = { T0, T1, T2, ..., Tn-1 } with n extended binary trees from the given n weights {w0, w1, w2, ..., wn-1}, where each The extended binary tree TI has only one root node with a weight wi, and its left and right subtrees are all empty.
2. Repeat the following steps until there is only one tree left in F:
1 Select the extended binary tree with the lowest weight of the two root nodes in F, and construct a new binary tree as the left and right subtrees. The weight of the root node of the new binary tree is the sum of the weights of the root nodes on the left and right subtrees.
2 Delete the two binary trees in F.
3 Add the new binary tree to F.
#include "stdio.h"
#include "stdlib.h"
#include 《string.h》
#define MAX 32767
Typedef char *HuffmanCode;
Typedef struct
{
Int Weight;//The right of the letter
Int Parent,Leftchild,Rightchild;
}HuffmanTree;
Void Select(HuffmanTree *HT, int n, int *s1, int *s2)
{
Int min1=MAX;
Int min2=MAX;
Int pos1, pos2;
Int i;
For(i=0;i"n;i++)
{
If(HT[i].Parent==-1)//Select a node that does not have a father yet
{
If(HT[i].Weight"=min1)
{
Pos2 = pos1; min2 = min1;
Pos1 = i; min1=HT[i].Weight;
}
Else if(HT[i].Weight"=min2)
{
Pos2 = i; min2=HT[i].Weight;
}
}
}
*s1=pos1;*s2=pos2;
}
Void CreateTree(HuffmanTree *HT,int n,int *w)
{
Int m=2*n-1;//total number of nodes
Int s1,s2;
Int i;
For(i=0;i"m;i++)
{
If(i"n)
HT[i].Weight=w[i];
Else
HT[i].Weight=-1;
HT[i].Parent=-1;
HT[i].Leftchild=-1;
HT[i].Rightchild=-1;
}
For(i=n;i"m;i++)
{
Select(HT,i,&s1,&s2);//This function selects the two nodes with the smallest weight from 0 to n-1
HT[i].Weight=HT[s1].Weight+HT[s2].Weight;
HT[i].Leftchild=s1;
HT[i].Rightchild=s2;
HT[s1].Parent=i;
HT[s2].Parent=i;
}
}
Void Print(HuffmanTree *HT,int m)
{
If(m!=-1)
{
Printf("%d", HT[m].Weight);
Print(HT, HT[m].Leftchild);
Print(HT, HT[m].Rightchild);
}
}
Void Huffmancoding(HuffmanTree *HT, int n, HuffmanCode *hc, char *letters)
{
Char *cd;
Int start;
Int Current, parent;
Int i;
Cd=(char*)malloc(sizeof(char)*n);//Used to temporarily store the encoding result of a letter
Cd[n-1]='\0';
For(i=0;i"n;i++)
{
Start=n-1;
For(Current=i,parent=HT[Current].Parent; parent!=-1; Current=parent,parent=HT[parent].Parent)
If(Current==HT[parent].Leftchild)//Judge whether the node is the left or right child of the parent node
Cd[--start]='0';
Else
Cd[--start]='1';
Hc[i]=(char*)malloc(sizeof(char)*(n-start));
Strcpy(hc[i],&cd[start]);
}
Free(cd);
For(i=0;i"n;i++)
{
Printf("letters:%c,weight:%d,coded as %s", letters[i], HT[i].Weight,hc[i]);
Printf("");
}
}
Void Encode(HuffmanCode *hc, char *letters, char *test, char *code)
{
Int len=0;
Int i,j;
For(i=0;test[i]!='\0';i++)
{
For(j=0;letters[j]!=test[i];j++){}
Strcpy(code+len,hc[j]);
Len=len+strlen(hc[j]);
}
Printf("The Test : %s Encode to be :",test);
Printf("%s",code);
Printf("");
}
Void Decode(HuffmanTree *HT, int m, char *code, char *letters)
{
Int posiTIon=0,i;
Printf("The Code: %s Decode to be :",code);
While(code[posiTIon]!='\0')
{
For(i=m-1;HT[i].Leftchild!=-1&&HT[i].Rightchild!=-1;position++)
{
If(code[position]=='0')
i=HT[i].Leftchild;
Else
i=HT[i].Rightchild;
}
Printf("%c", letters[i]);
}
}
Int main()
{
Int n=27;
Int m=2*n-1;
Char letters[28]={'a','b','c','d','e','f','g','h','i','j','k' , 'l', 'm',
'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z ',' '};
Int w[28]={64,13,22,32,103,21,15,47,57,1,5,32,20,
57,63,15,1,48,51,80,23,8,18,1,16,1,168};
Char code[200];
Char test[50]={"this is about build my life"};
HuffmanTree *HT;
HuffmanCode *hc;
HT=(HuffmanTree *)malloc(m*sizeof(HuffmanTree));
Hc=(HuffmanCode *)malloc(n*sizeof(char*));
CreateTree(HT,n,w);
Print(HT,m-1);
Printf("");
Huffmancoding(HT,n,hc,letters);
Encode(hc,letters,test,code);
Decode(HT,m,code,letters);
Printf("");
Return 0;
}
Recommended reading:
How to implement Huffman coding and decoding in c language
Huffman encoding and decoding by java
Huffman algorithm understanding and principle analysis, algorithm implementation, algorithm for constructing Huffman tree
Regular GFCI Receptacle Outlet
Lishui Trimone Electrical Technology Co., Ltd , https://www.3gracegfci.com