Parallel Optimization of 2D Floating-Point Matrix Operation Based on Mali-T604 Embedded GPU
The ARM Cortex-A15 series processors are the latest embedded ARM SoCs. This series of processors integrates the mobile-side GPUs of the Mali-T600 series for the first time. The series of GPUs support computing frameworks such as OpenGL and OpenCL, which can effectively accelerate general-purpose computing. At present, there are few studies on its application methods and actual optimization effects. Based on the Arndale Board embedded development platform based on Samsung's Exynos 5250 processor, this paper studies the GPGPU (General-Purpose computaTIon on GPU) technology of the Mali-T604 embedded GPU integrated on the processor and calculates the scale of different operations. Floating-point matrix multiplication performs parallel acceleration optimization to provide actual test results.
In the early years, GPGPU technology mainly used high-performance computing on supercomputer platforms. In recent years, this technology has gradually been introduced into the embedded field. However, in the past, there was no software framework and programming interface for general computing on the mobile GPU platform. It is difficult for software designers to control the synchronization of data and parallel computing, so mobile GPU has been difficult to apply in the field of general computing. Based on the Exynos5250 SoC platform, this paper describes the hardware characteristics of Mali GPU and the method of applying it to general-purpose computing. Finally, the parallelization of 2D floating-point matrix multiplication is taken as an optimization example to verify the parallel capability of Mali GPU. Researchers and application developers of GPU GPGPU technology provide technical reference and reference.
1.Mali T604 GPU hardware structure and programming features
Mali is a series of mobile display chipsets (GPUs) designed and developed by ARM. It not only provides powerful image rendering capabilities on the mobile side, but also supports hardware and software support for general-purpose computing in the near future.
1.1 Mali T604 GPU composition
The Mali-T604 is the first mobile GPU in the Mali series to use the unified rendering architecture Midgard. The Mali-T604 GPU includes four shader cores, featuring the AMBA 4 ACE-LITE bus interface, which features Cache Coherent Interconnect technology. Provides full Cache coherency between processors. Through ARM's consistency and interconnect technology, computing tasks can easily access data across CPUs, GPUs, and other available computing resources while sharing processing in heterogeneous systems. . Figure 1 shows the basic framework of the Mali-T604 GPU. As shown in Figure 2, the Cortex-A15 CPU core and the Mali GPU core physically share off-chip RAM memory and maintain L2Cache consistency.
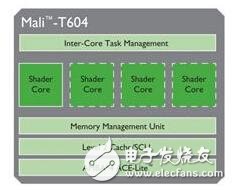
Figure 1 Mali-T604 basic hardware block diagram
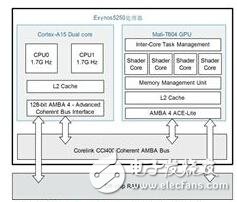
Figure 2 Exynos5250 processor block diagram
The Mali-T604 GPU optimizes task management and event-dependent processing at the hardware level and fully integrates this functionality into its hardware task management unit, offloading compute tasks from the CPU to the GPU, and coloring the activity Seamless load balancing between the cores.
1.2 Mali GPU parallelization thread structure features
The core of the Mali GPU for general-purpose computing is to disassemble intensive computing tasks with the idea of ​​multi-core and multi-threading, and allocate a large number of computing threads to many computing cores. The GPU can process hundreds of threads at the same time, and a large number of transistors are used. ALU.GPU is suitable for parallel computing of high-density data, and can only exert powerful parallel computing power when the parallel granularity of the operation is large enough. Figure 3 shows the process of working between the CPU and the Mali GPU.
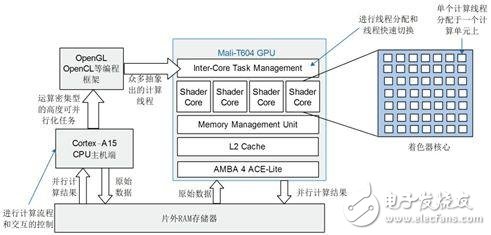
Figure 3 Working between the Cortex-A15 CPU and the Mali GPU
Each computing thread in the Mali GPU occupies a portion of the resources of the shader core (memory, ALU, etc.), and the amount of resources consumed by each thread affects the number of active threads that are simultaneously processed in parallel. For Mali GPUs, each thread has its own program counter, which means that the Mali GPU is different from the desktop GPU platform, and the divergence of program branches is not an important issue affecting efficiency. The shader core of each Mali-T604 GPU can accommodate up to 256 threads at the same time. Mali GPU requires a large number of threads to switch in general computing to ensure the gain of computational efficiency. For Mali-T604, this is the least. The total number of work items is 4096. If the number of threads allocated on a single shader core is less than 128, it is likely to cause a drop in parallel efficiency, which requires splitting the work into different steps, simplifying the thread complexity of each step, Let the number of threads that a single shader core hold in parallel enough to guarantee parallelism.
2.Mali GPU parallel computing model construction
The Mali-T600 series of GPUs support the OpenCL 1.1 Full Profile standard. OpenCL is a truly cross-platform heterogeneous parallel framework that can truly mine the parallel computing features of the Mali GPU.
2.1 Parallel task abstraction and thread planning of Mali GPU in OpenCL framework
OpenCL is a cross-platform heterogeneous parallel computing framework consisting of programming language specification, application programming interface, library function and runtime system. The abstraction level of Mali-T604 GPU under OpenCL is shown in Figure 4 below:
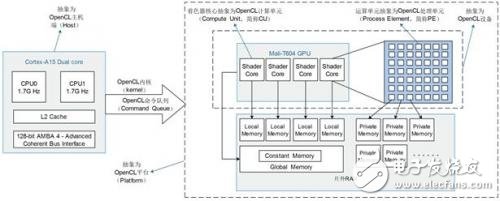
Figure 4 OpenCL for the abstraction level of Mali-T604
The parallelism of OpenCL is based on the idea of ​​SMT (simultaneous multi-threading). The user specifies a custom number of threads, and designs the mapping rule of thread and data association according to the identifier of the thread. The SMT architecture is mainly used for the delay of hidden memory access. Under the OpenCL framework, the CPU host-side program is written by the OpenCL API to implement initialization of the computing platform, memory allocation and interaction control, and to determine the dimensions of the allocated computation thread and the number of each dimension. The kernel program on the device side is written by OpenCL C language. The Mali GPU creates a thread instance of the number of requests from the host according to the kernel object. The operation of each thread is processed by a corresponding PE in Figure 4. The thread's working logic determines the thread. The relationship between the identification number and the data. Multiple threads are organized into workgroups. Each workgroup is fixedly allocated to one CU for processing. The threads in the same workgroup are quickly switched and scheduled by the Mali GPU task management unit on the corresponding CU. To ensure that the PE on a CU is kept busy to the maximum.
2.2 Memory space mapping method in Mali GPU multi-core environment
As shown in Figure 4, the RAM shared by the Mali GPU and the Cortex A15 CPU is logically cut into four different types by the OpenCL framework. The Mali-T600 series of GPUs use the unified memory model, and all four types of memory are mapped to On off-chip RAM, the Cortex-A15 CPU and the Mali-T604 GPU share physical RAM. Compared to the desktop GPU platform, copying data from global memory to local or private memory on the Mali platform does not improve the memory access performance. Relatively, there is no need to copy data from main memory to video memory like a desktop GPU. The Mali GPU has three ways to access the RAM, which is determined by the different parameters passed into the clCreateBuffer function. The schematic diagram is as follows:
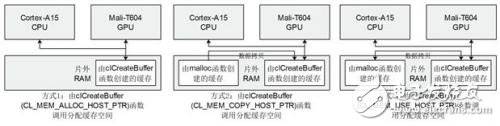
Figure 5 Different access methods of the Mali GPU to the memory under the OpenCL framework
The Cortex-A15 CPU and the Mali-T604 GPU use different virtual address spaces, and the cache allocated by the malloc function on the host side cannot be accessed by the Mali GPU. The Mali GPU can access the cache allocated by the clCreateBuffer function. The CPU can also read and write such caches by means of the map mapping operation in OpenCL. The mode 2 in Figure 5 requires the host side cache to perform data copying to initialize, mode 3 and mode. 2 similar, but only when the kernel function of OpenCL uses the cache for the first time, the data is copied. When the map operation is performed on the CPU side, the GPU will copy the data back to the cache of the host. For the Mali GPU, the redundant data copy operation will be performed. Reduce the efficiency of access. The mode 1 in FIG. 5 is an ARM recommended memory access mode, and the CPU and the GPU share a physical cache to implement data interaction at high speed.
2.3 Mali GPU vector processing features
The Mali-T604 GPU has a 128-bit wide vector register. The built-in vector type in OpenCL C allows data to be automatically calculated in the form of SIMD in the ALU of the Mali GPU. The data in the Mali GPU is 16 bytes. Alignment allows data length and cache adaptation to speed up data access. The time it takes to load a 128-bit vector in a Mali-T600 series GPU is the same as loading a single-byte data. Aligning the data with 128 bits maximizes the memory and computational efficiency of the Mali-T604 GPU.
3. Realization of fast floating point matrix multiplication parallelization based on Mali-T604 GPU
Matrix multiplication has been widely used in path solution solving, linear equation solving, image processing, etc. The time complexity of ordinary iterative serial algorithm is O(n3), for large matrix multiplication, especially floating point type. Matrix multiplication, the amount of calculation is very amazing, the traditional algorithm is based on CPU design, CPU can not provide large parallelism and powerful floating-point computing power, the processing power of large floating-point type matrix multiplication is not enough.
The result of multiplication of the two matrixes of AB depends on the dot product of one row in A and one column in B. Each calculation result has no dependence and correlation, which is obviously a highly data-parallel computing problem. It is very suitable for parallel processing using GPU. Multiple threads on the GPU can parallelize the dot product of different rows and columns in matrix A and B.
In the actual experiment, multiply the two floating point matrices A and B of N*N to obtain the N*N floating point result matrix matrixResult. When using the Mali GPU for parallelization, a total of N*N threads are allocated. Arranged in two dimensions, the thread with the identification number (i, j) extracts the i-th row of the matrix matrixA and the j-th column of the matrix matrixB, and quickly implements two ones using the float4 vector type of 128 bits in OpenCL. The dot product of the dimension vector, which is then stored in the matrixResult[i] [j] position. The code segment of the host-side allocation thread is as follows:

The author sets the workgroup size parameter in the clEnqueueNDRangeKernel function to NULL, and the Mali GPU hardware automatically determines the optimal workgroup size. Since the kernel reads 4 floating-point values ​​continuously for each time of the float4 type data, special processing is required for the case where the width of the matrix is ​​not a multiple of 4, and the input matrix A can be first modified to N rows on the host side. N/4+4 columns, the matrix B is modified to N/4+4 rows and N columns, and the extra matrix parts are all filled with 0, so that the calculation result is not affected, and the allocation scheme of the thread is not affected, and parallel implementation is realized. The kernel function of the scheme is as follows:

This article uses the Arndale Board development board as the test platform. The software platform uses the Ubuntu-based embedded Linux operating system customized by Linaro for the Arndale Board. The kernel version is 3.10.37. The experiment is performed using the arm-linux-gnueabihf toolchain. Compile. Test results of the serial scheme of the two-dimensional floating-point matrix multiplication on different scales on the ARM Cortex-A15 CPU and the parallel scheme on the Mali-T604 GPU are shown in Table 1, without loss of generality, input during testing. The contents of the matrix are random values, and each test item of different matrix size is tested 10 times, and the average value of the test values ​​is taken as the test result.
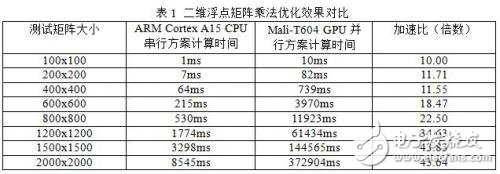
The above table only lists the test results when the input amount is large. When the author actually tests, when the input data volume is small, the parallel scheme has no high efficiency of the serial scheme, because most of the calculation process is consumed in the data transmission. On the other hand, because the calculation amount is small, the calculation on the GPU side is completed instantaneously, and there is no way to mask the delay of the Mali GPU memory access. Therefore, the serialization scheme of the CPU side with faster access speed is more efficient.
When the amount of calculation is gradually increased, the parallel power of Mali GPU gradually shows its advantages, and the acceleration ratio is significantly improved. When the amount of calculation is large to a certain extent, the acceleration ratio tends to be stable, because there are a large number of Mali GPUs. Thread switching not only hides the delay of memory access, but also makes the computing unit on the Mali GPU full, and its computational efficiency has reached the limit that the hardware can withstand. At this time, the Mali GPU can provide nearly 40 times for the amazing speedup.
In the actual test, the author uses the top instruction to observe the CPU usage of the matrix process. The CPU usage of the serial scheme is about 98%, and the parallel scheme based on Mali GPU has almost no CPU consumption, indicating that the parallel scheme can not only improve the computational efficiency. It also reduces the burden on the CPU and greatly improves the real-time performance of the system. The actual test results of the experiment are consistent with the characteristics of the GPU heterogeneous operation.
4. Conclusion
This paper discusses the parallel optimization of general computing on the OpenCL-based Linux platform for the Mali-T604 GPU, discusses the hardware features of the Mali-T604 GPU, and designs a parallel scheme of two-dimensional matrix multiplication based on OpenCL, on the Mali-T604. Obtaining an amazing speedup, the results show that the Mali GPU has significant acceleration capability for computationally intensive, highly data-parallelizable general-purpose computing problems with large input quantities, and the parallel optimization results are correct and reliable.
Outdoor Commercial LED Light,Outdoor Wall Pack Lights,Waterproof LED Wall Pack Light,Wall Pack Lamp For Garden
Vietnam JJ Lighting Company , https://www.vnjjlighting.com